So for one of the projects I am working on I have to deal with large Json files. My first instinct is to use what I know: R, python, bash… But this time I had to use a tool that was new to me, JQ, with great results.
The problem with R is everything needs to be processed in memory. This is not a problem if you have access to cloud computing. As we do with UCloud from SDU. It is a dirty solution to brute force the problem by throwing hardware at it. Especially considering how inefficient some R code can be (when speed is an issue R functions call outside code often developed in C++). Problem was UCloud only allowed access to R Studio. I needed batch processing (both for efficiency and stability). So R was out.
Then I considered my old love affair with bash, awk and sed from sys admin days. sed was easy enough to use but the stuff I needed required some manual processing after. The code I came up with was clumsy and this too at the end was not an elegant solution. So sed was out.
That made me think. Json being so popular, I probably am not the only one that requires something like this. Someone else must have had this problem and developed a solution. Sure enough. There is a very efficient command line Json editor called JQ.
I was hesitant to give it a go at first. I didn’t want to spend time learning something that may or may not be useful, when I could use the time to do it with one of the tools I knew. Boy was I wrong. It took me an afternoon to learn JQ, and a one liner processed the data and made it immediately usable for modelling without ever pulling R or Python into the problem.
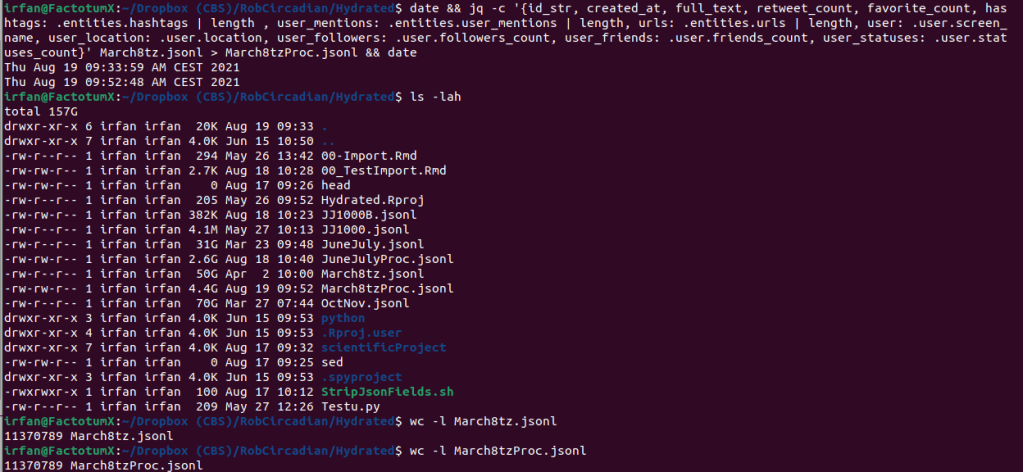
The kicker is it is extremely fast compared to any of my other solutions. 50GB of Json, chewed and swallowed in less than 20 minutes on my work machine.

Leave a comment